
Eric Wang
October 27, 2021
李宏毅-机器学习2021春-6
李宏毅-机器学习2021春-6
1 GNN
2 Deeep Reinforcement Learning (RL)
当人类也不知道什么是好的输出结果时,可以用RL。
2.1 RL与机器学习的关系
Step 1 Function with unknown parameters
- 用sample产生随机输出
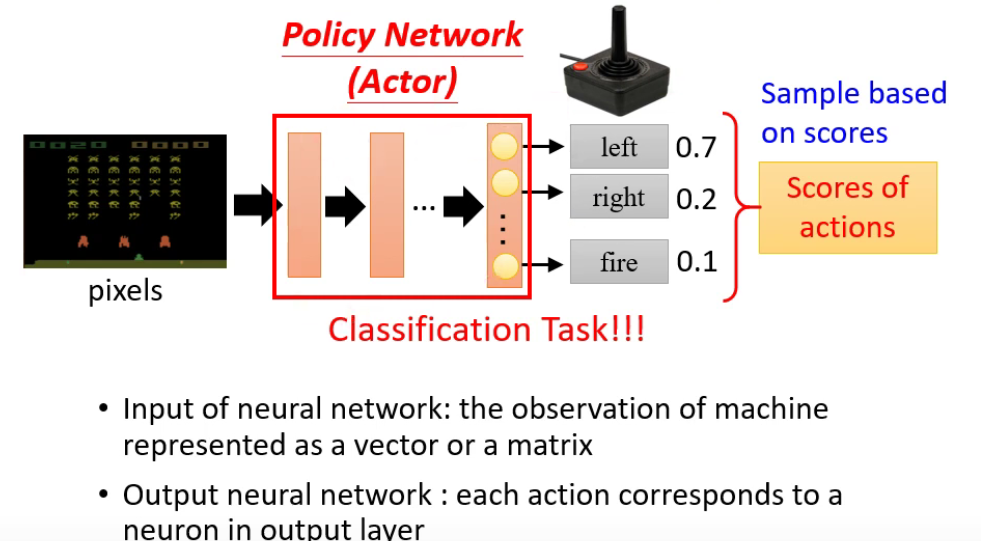
Step 2 Define “Loss”

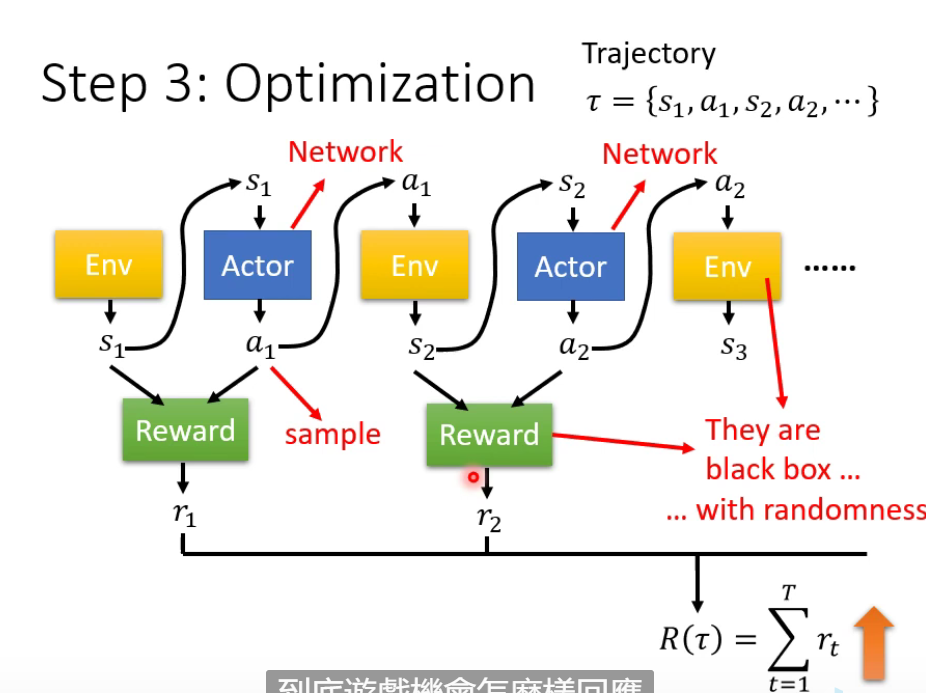
Step 3 Optimization
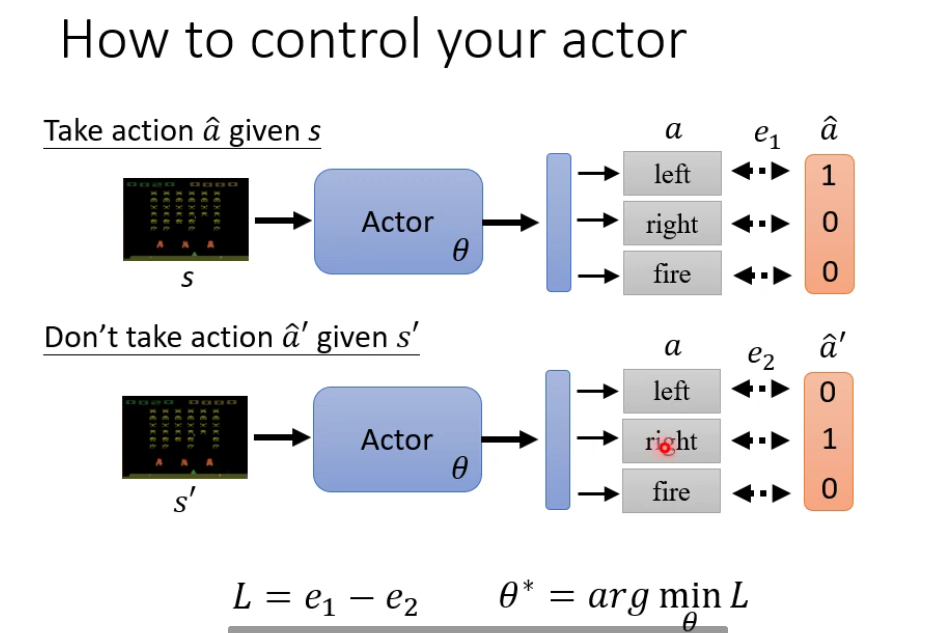
2.2 Policy Gradient
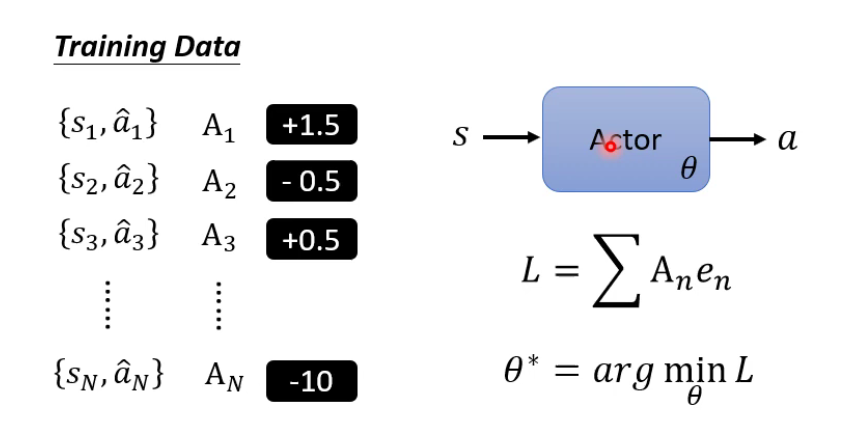
加入$A_n$,代表期望执行的程度。
- $\gamma$:learning rate
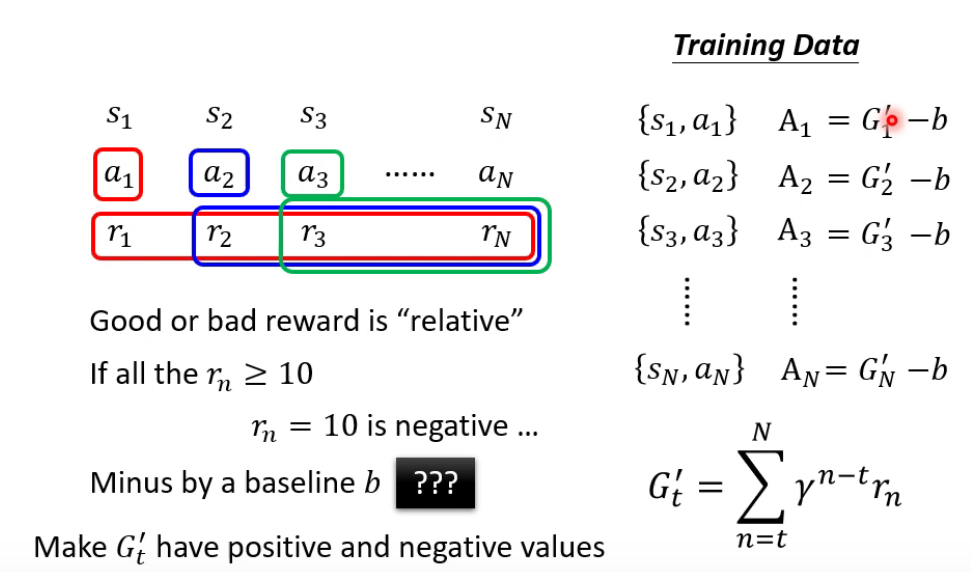
Policy Gradient的步骤:

On-policy & Off-policy
- On-policy:用于训练的actor和用于交互的actor相同。
- Off-policy:用于训练的actor和用于交互的actor不同。如Proximal Policy Optimization (PPO)。
2.3 Actor-Critic
- Montre-Carlo (MC) based approach
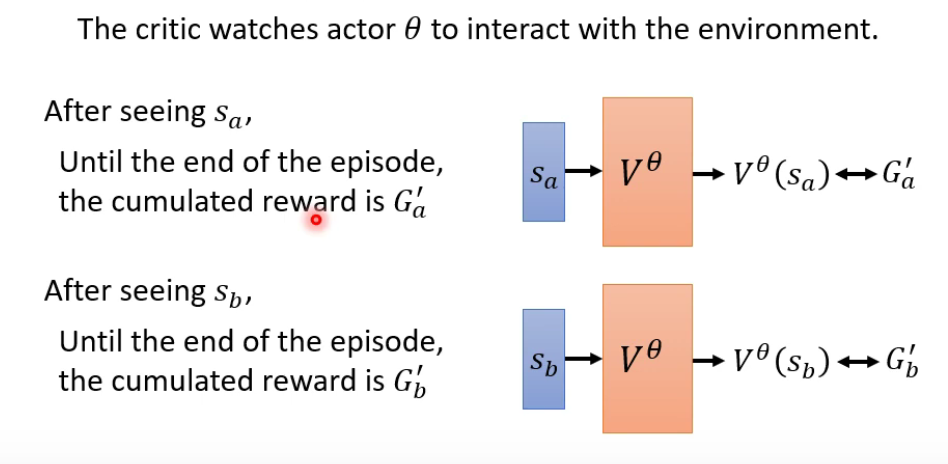
- Temporal-difference (TD) approach

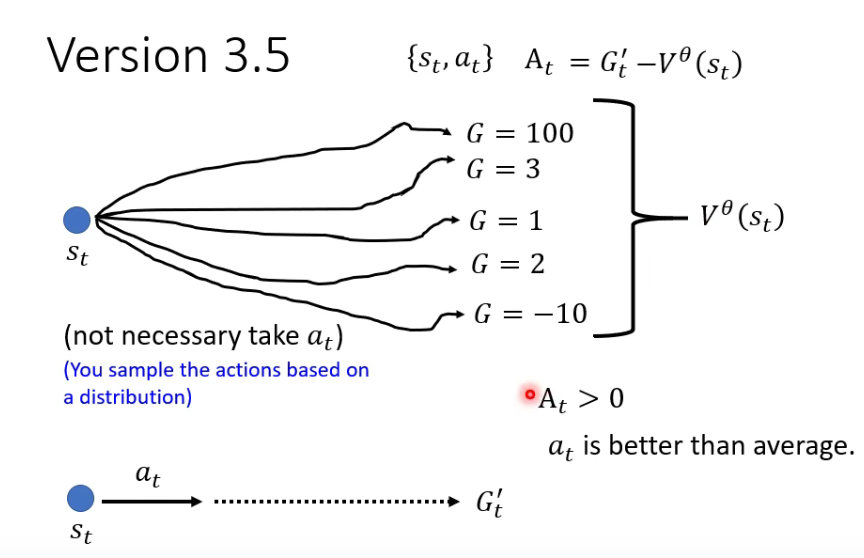
Veresion 3.5

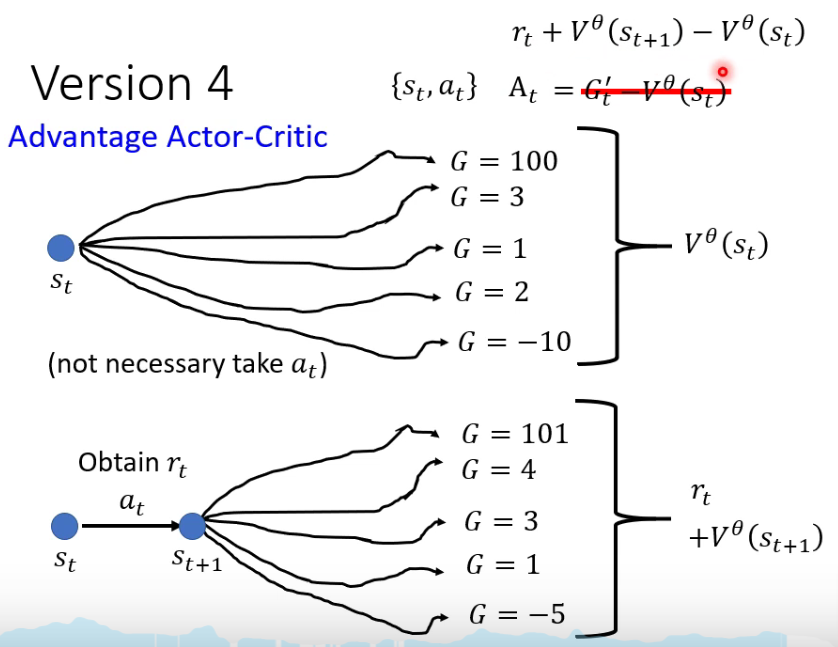
Version 4 —— Advantage Actor-Critic
Actor和Critic的参数可以共享:
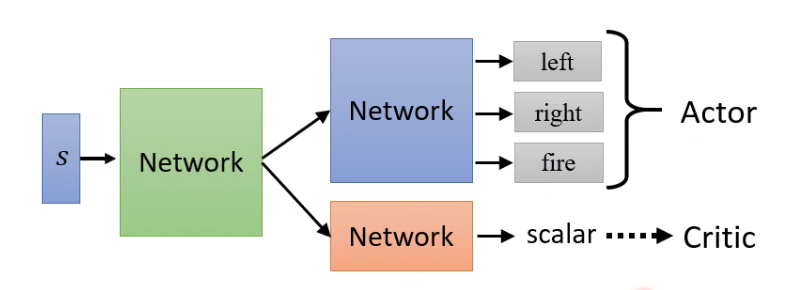
只采用Critic的方法:Q-learning(Rainbow)