
Eric Wang
October 17, 2021
李宏毅-机器学习2021春-4
李宏毅-机器学习2021春-4
1 Transformer
Sequence-to-sequence(Seq2seq)
- 输出的长度由模型决定
- Encoder+Decoder
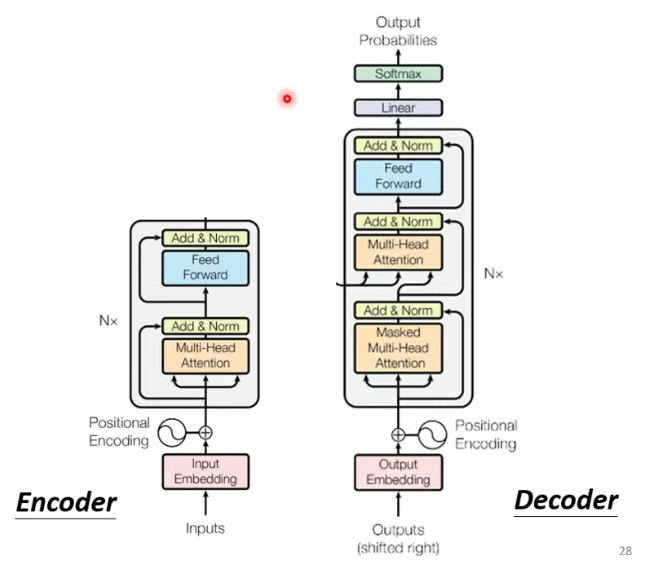
1.1 Encoder
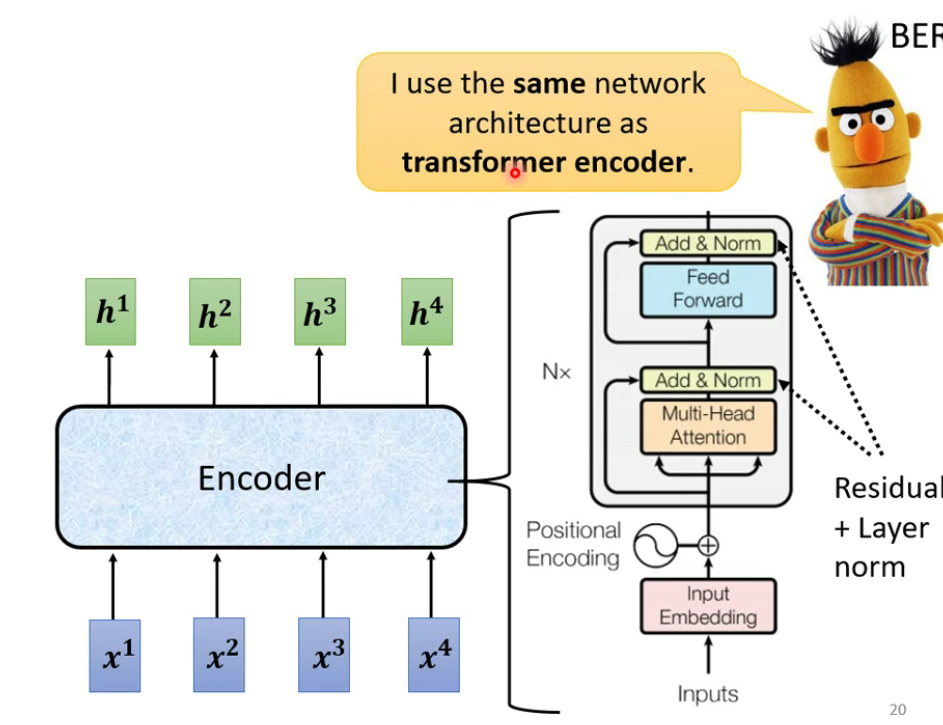
encoder内部由许多block组成:
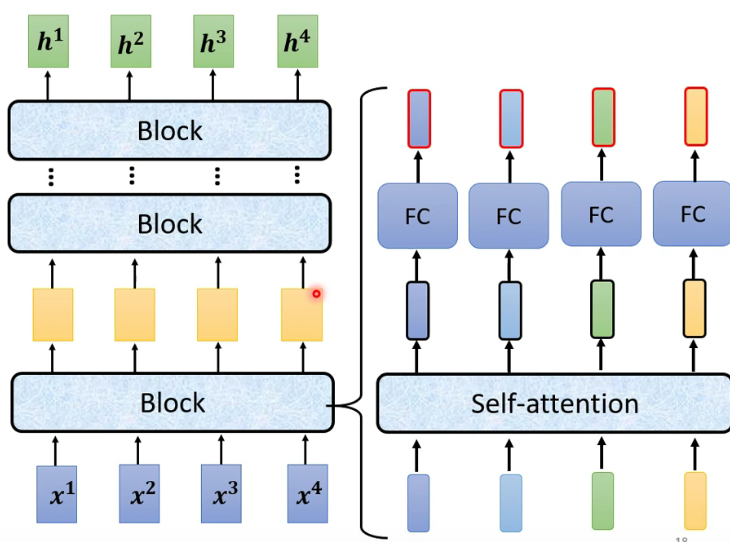
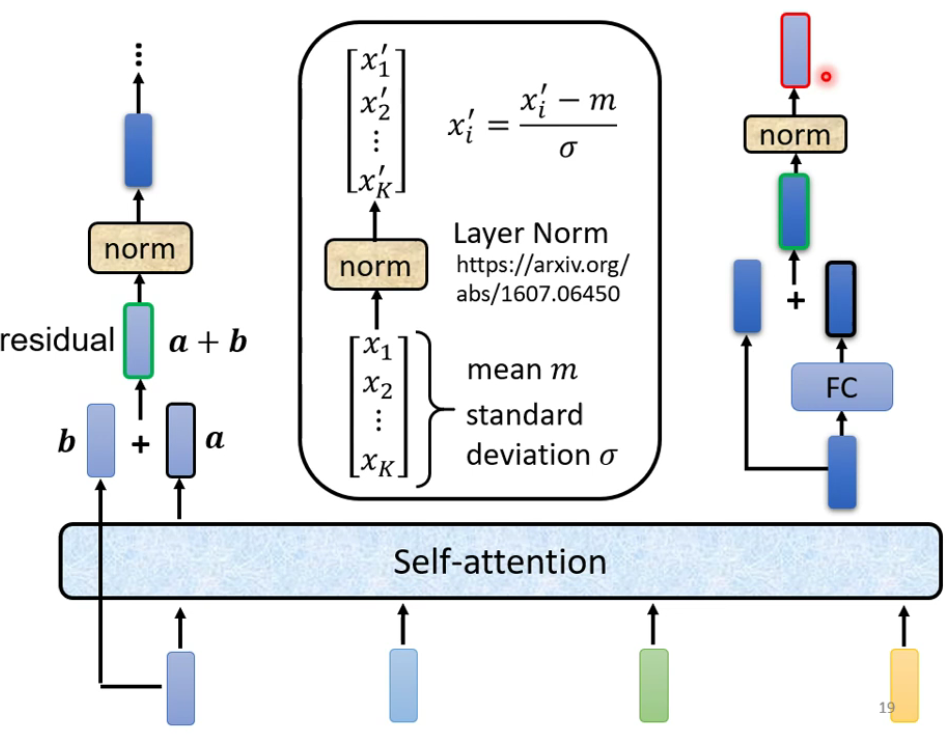
每个block的构成如下:
1.2 Decoder-Autoregressive(AT)
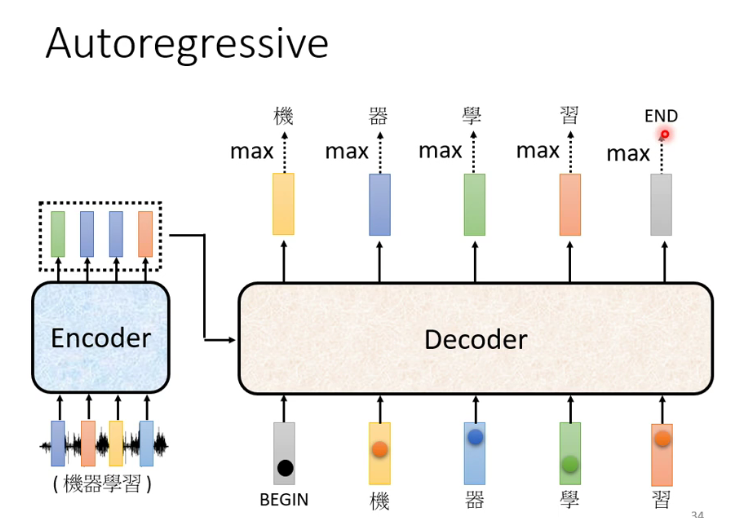
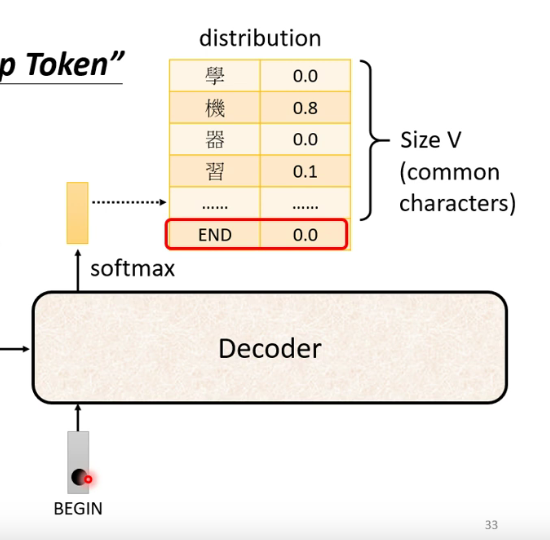
与Encoder的对比图:(Multi-Head Attention前加了一个Masked)
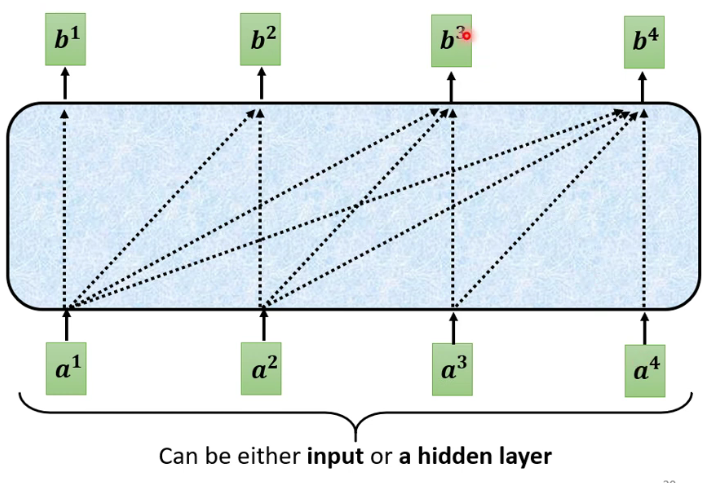
Masked Self-attention
- 产生$b^1$的时候只能考虑$b^1$的资讯。
- 产生$b^2$的时候只能考虑$b^1$、$b^2$的资讯。
- 产生$b^3$的时候只能考虑$b^1$、$b^2$、$b^3$的资讯。
1.3 Encoder-Decoder
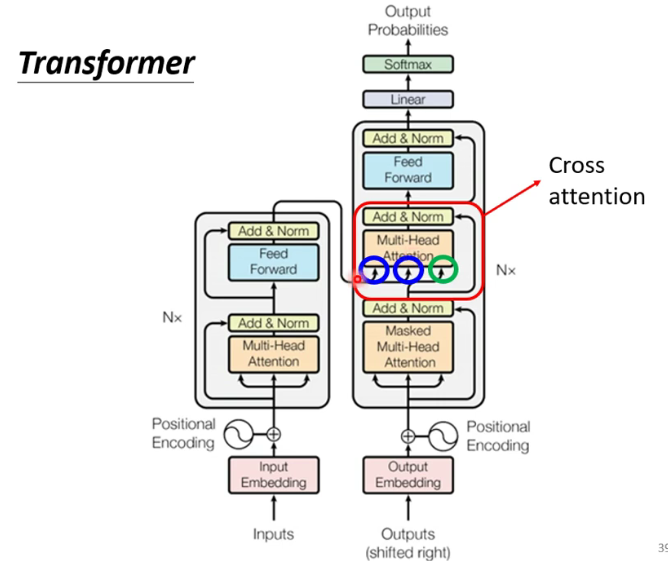
Cross attention:
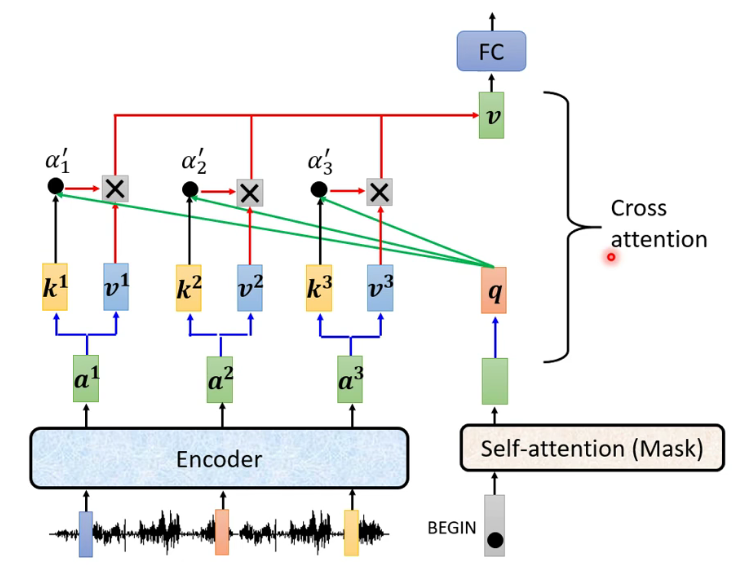
Teacher Forcing: 用ground truth(答案)作为Decoder的输入
1.4 Training Tips
- Copy Mechanism
- Guided Attention
- Beam Search:不基于贪心的一种搜索算法
2 BERT
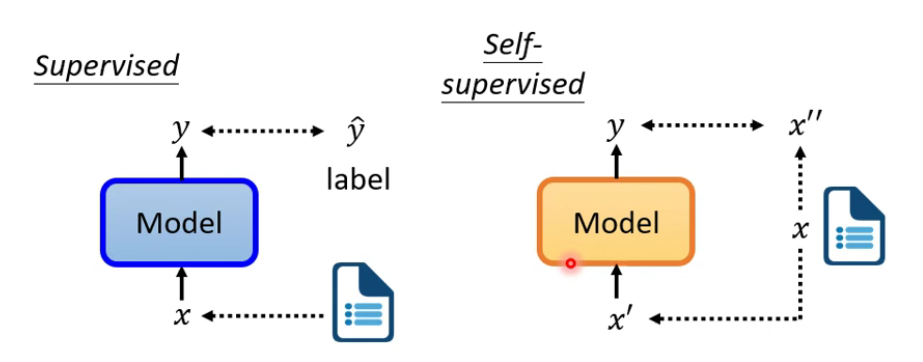
- Self-supervised Learning
系统通过输入数据的一部分进行predict,另一部分输入用于进行比对。
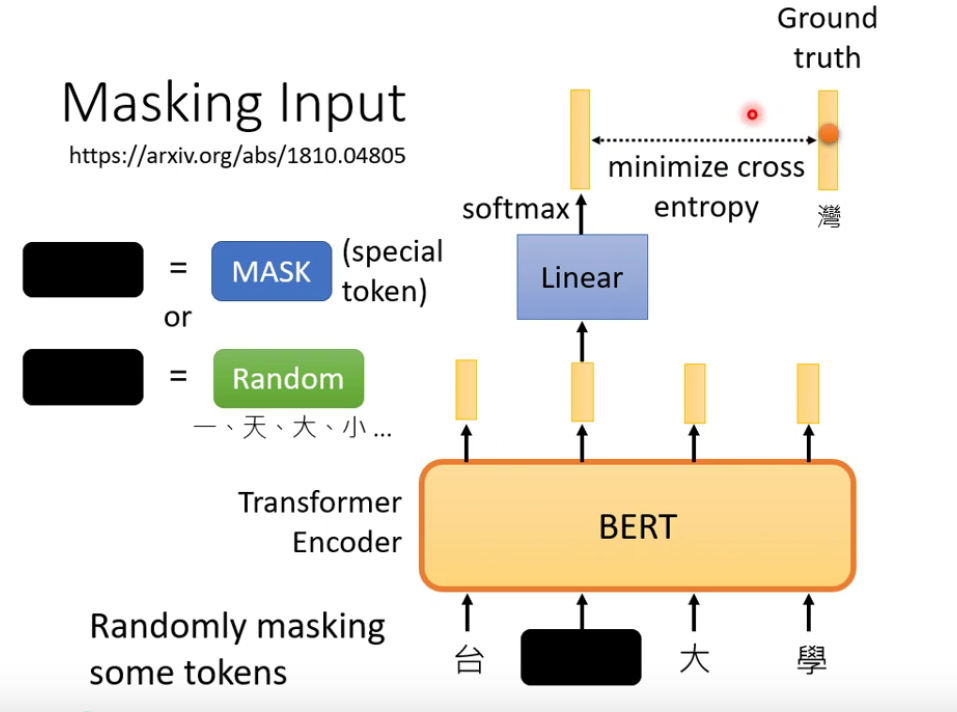
- Masking Input
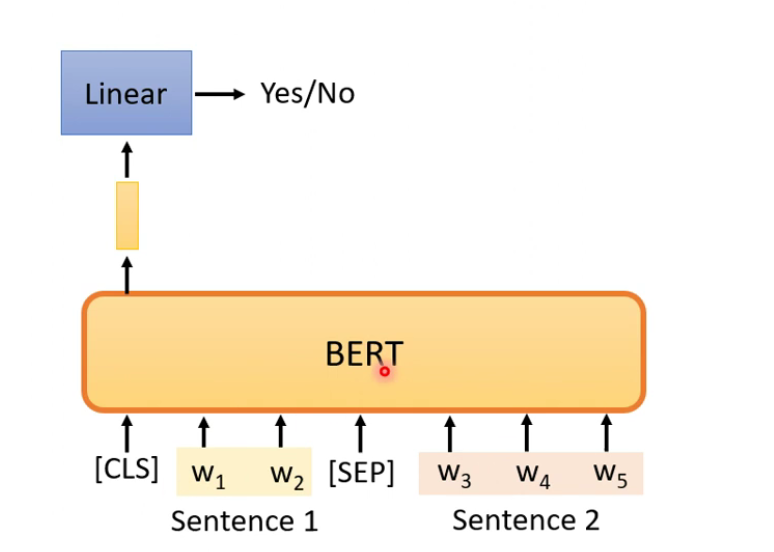
- Next Sentence Prediction
- 对于BERT不是很有用
BERT经过Fine-tune,可用于下游任务。
BERT整体是Semi-supervised的。填空题(Pre-train)阶段是Self-supervised,Finetune阶段是supervised。
2.1 Bert Case
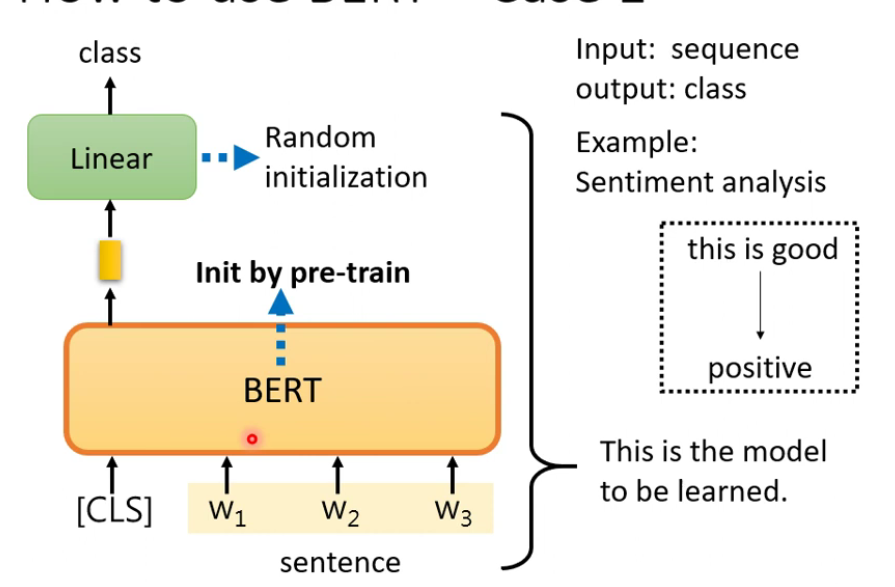
- 用于语义分析。输出类别。BERT是用填空题预训练的。
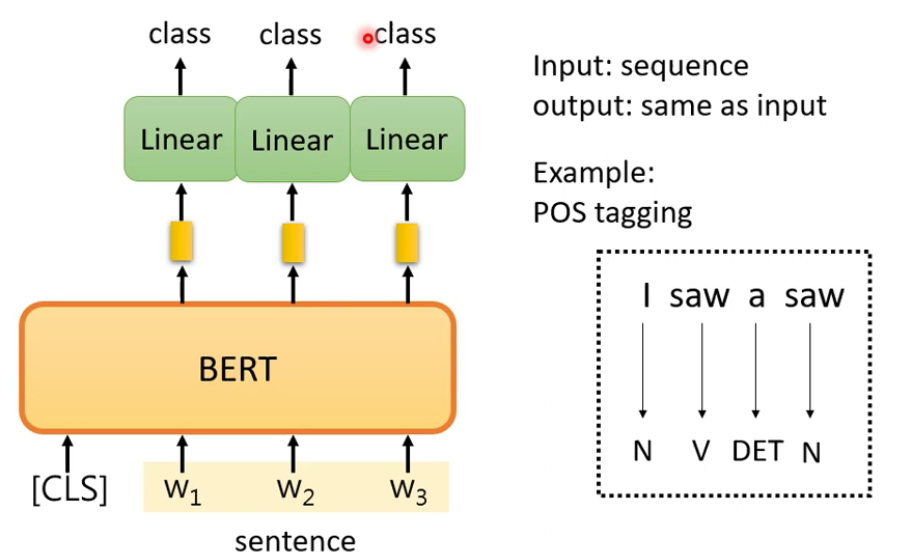
- 用于词性标注。输出和输出长度相同。
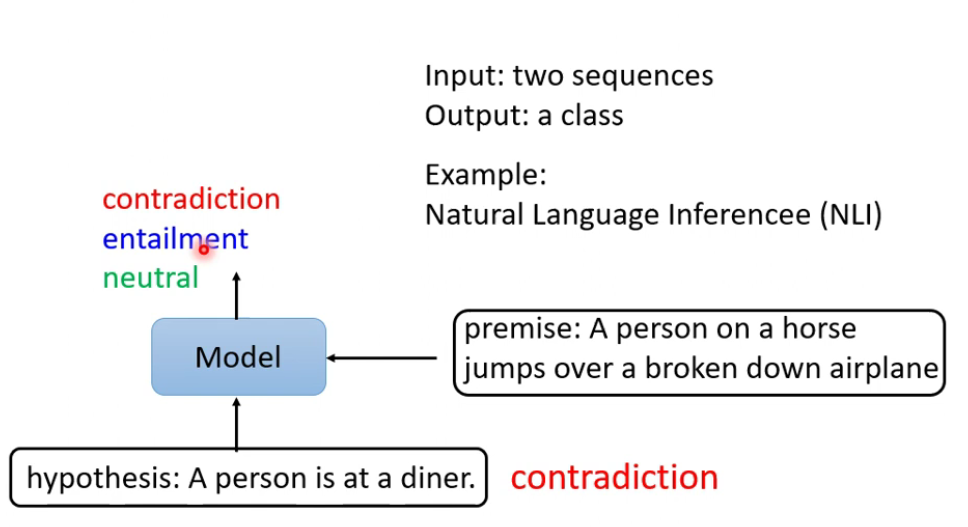
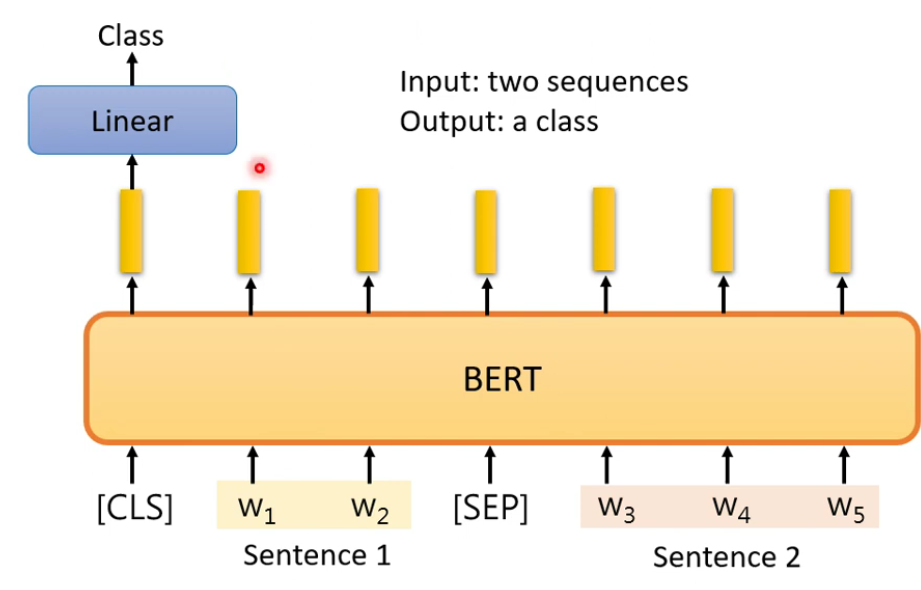
- 用于自然语言推测。输入两个句子,输出一个类别。
- 基于提取的问答系统
- 输入一个问题和一篇文档,输出答案的起始位置和结束位置。

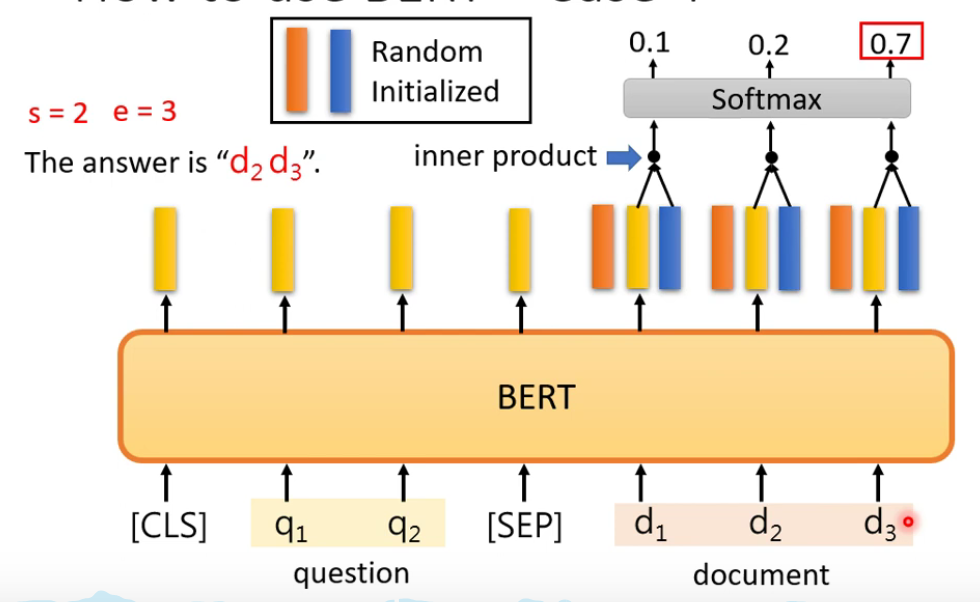
2.2 Bert的其它应用
Bert可以应用于蛋白质分类、DNA分类、音乐分类。
Multi-lingual BERT
用多种语言进行填空题训练。