
Eric Wang
October 17, 2021
李宏毅-机器学习2021春-3
李宏毅-机器学习2021春-3
1 Classification
将Class用one-hot vector表示
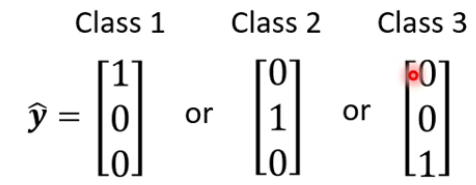
回归与分类的区别:

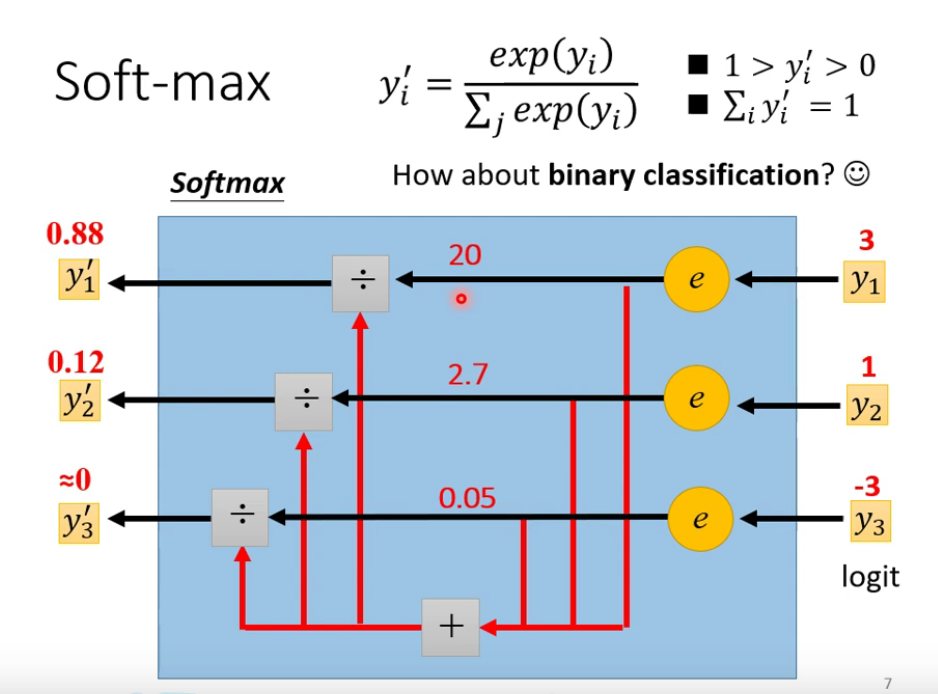
softmax:
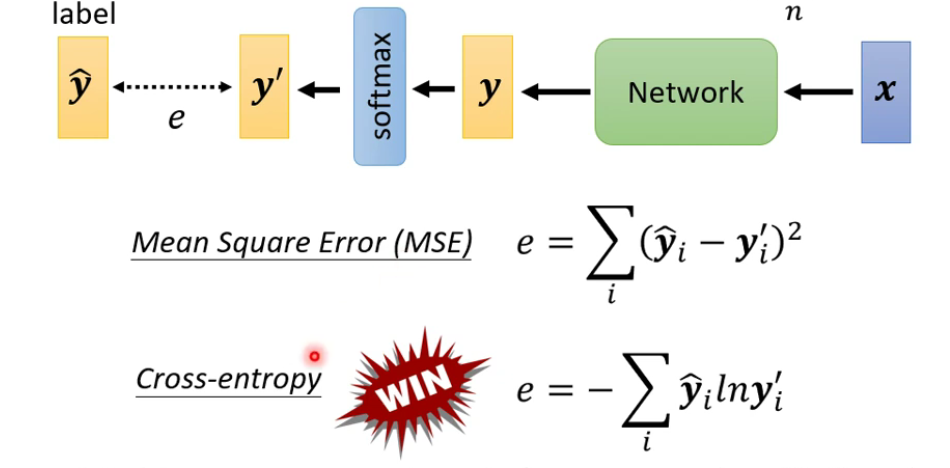
Loss的计算:
2 Convolutional Neural Network (CNN)
为Image Classification设计的网络。
默认Image大小为100*100。
- Receptive field(感受野):图像的一个局部特征
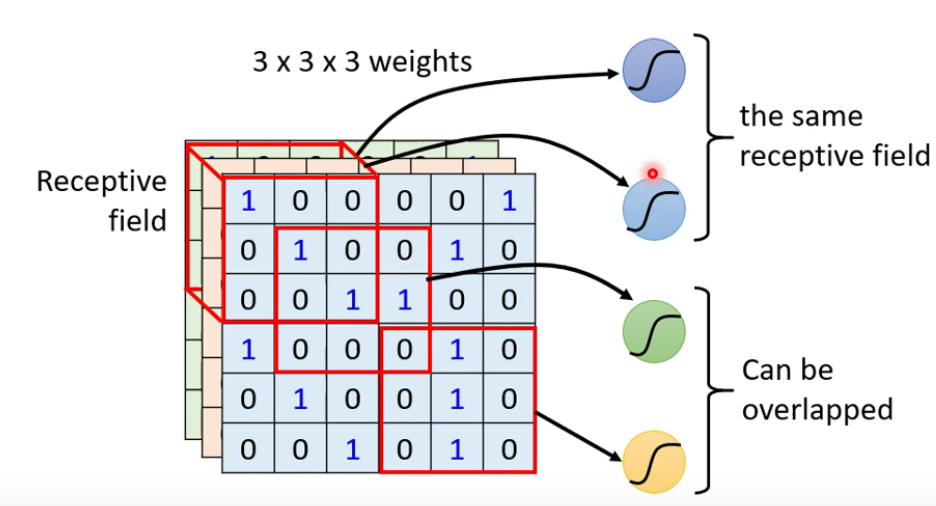
- 共享参数:w1,w2是相同的
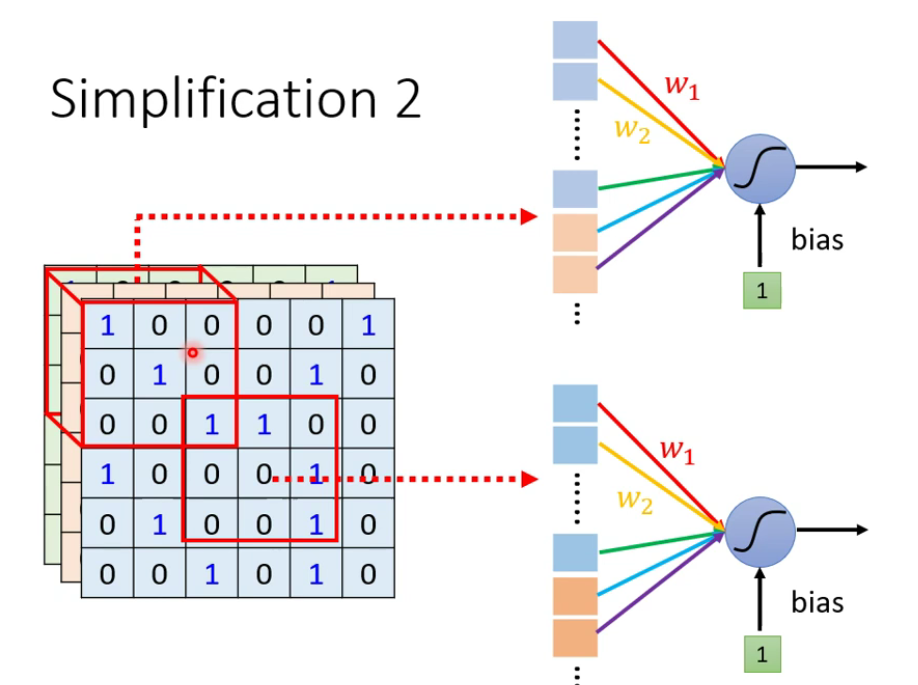
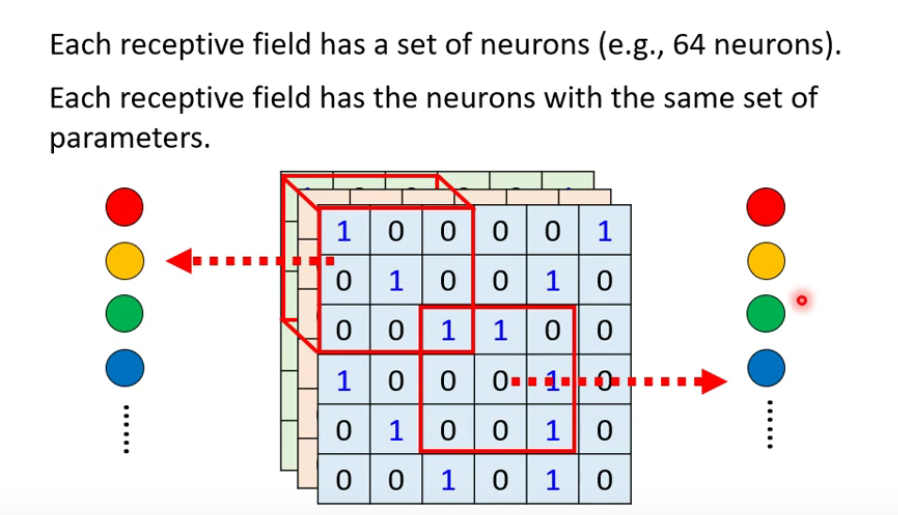
receptive field + sharing parameteres = convolutional layer
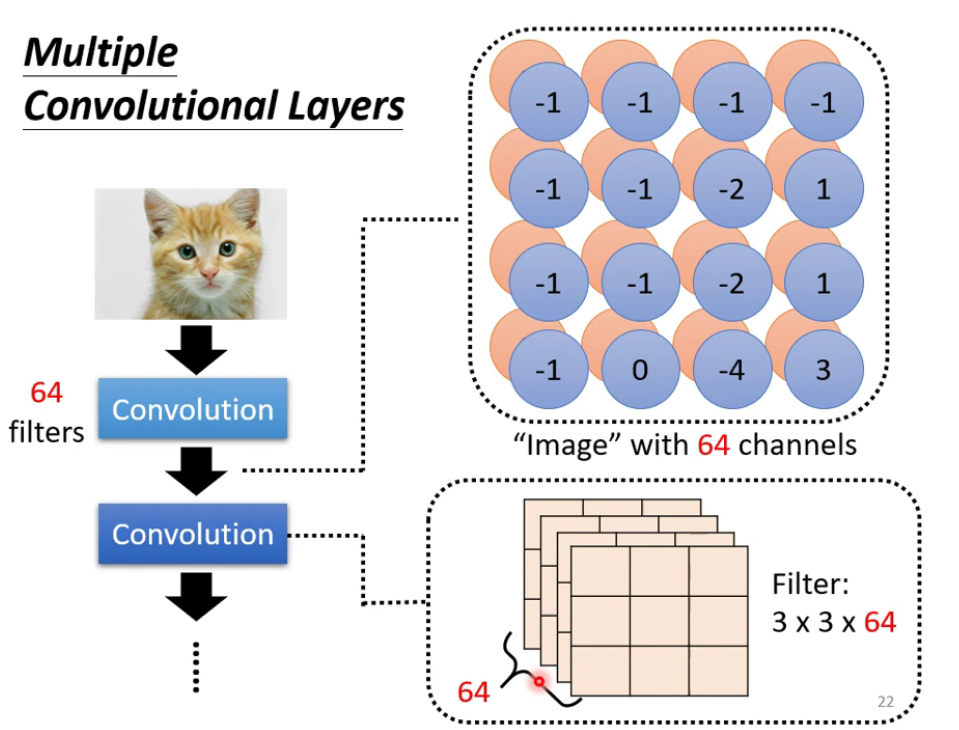
- Convolutional layer:由一堆Filter组成,Filter捕捉图片里的pattern。
- Feature Map:图片经过Convolution layer得到的结果
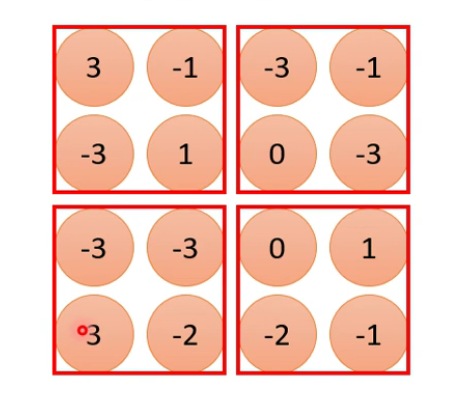
Pooling—Max Pooling
没有参数需要学习
Spatial Transformer Layer:解决CNN无法面对放大和旋转的问题
3 Self-attention
3.1 背景
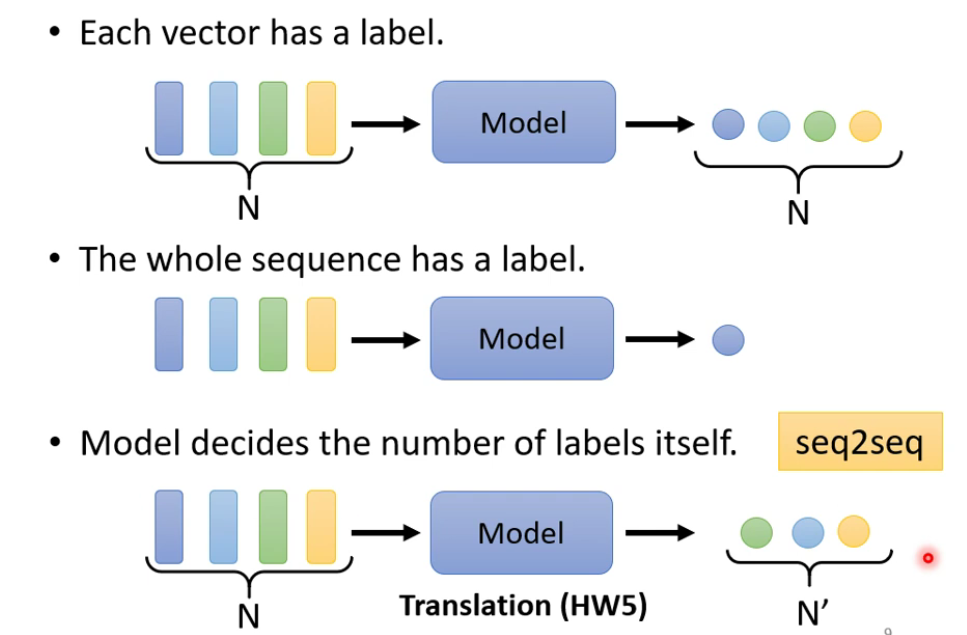
当输入是多组向量时,输出的情况:
- 每一个向量都有一个label(sequence labeling),此处可以用self-attention
- 整个sequence有一个label
- 模型自己决定输出长度(seq to seq)
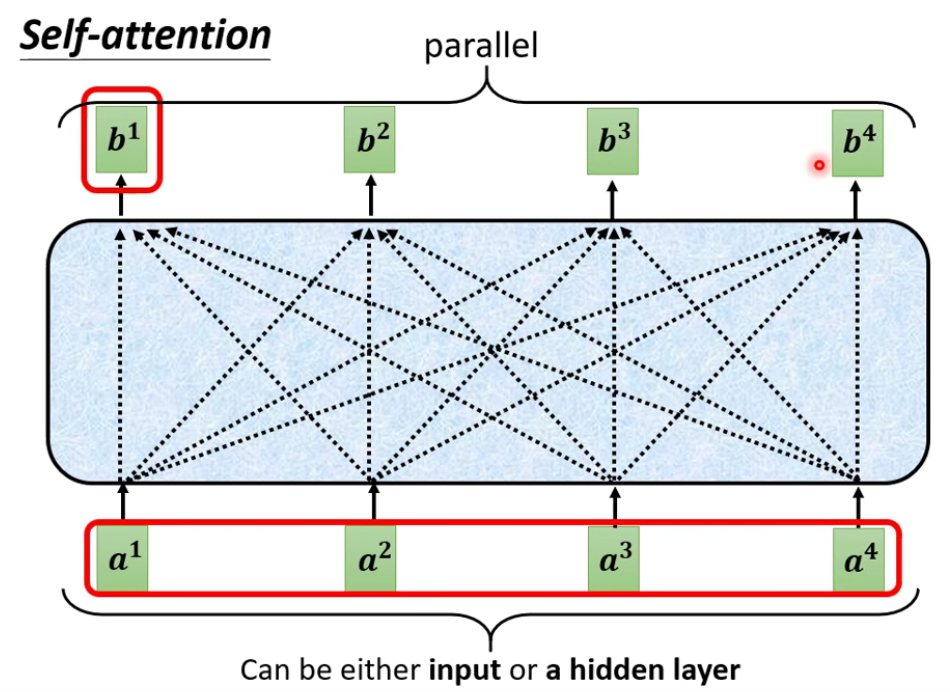
3.2 原理
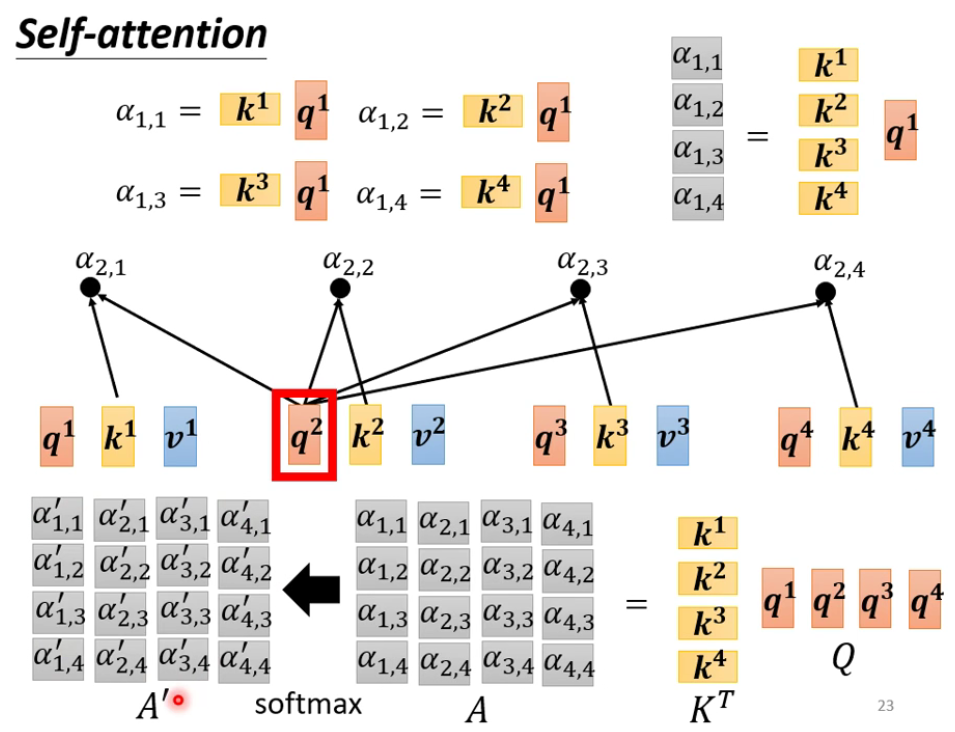
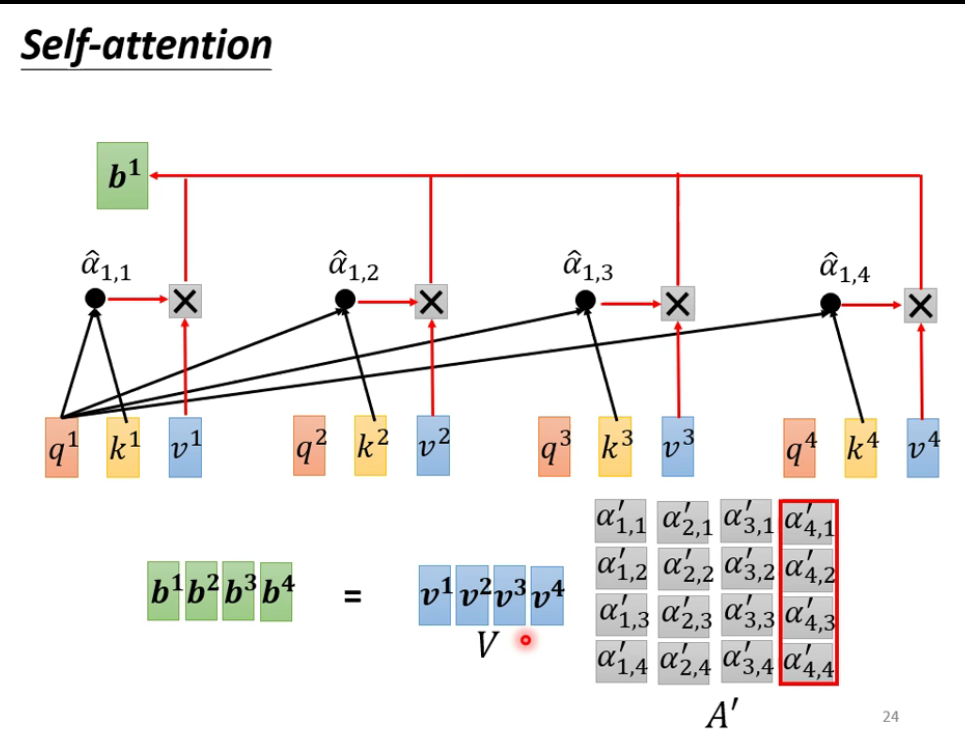
Self-attention的输出$b^1$,既代表$a^1$,又代表$a^1$和$a^2$、$a^3$的关系。
解释得到$b^1$的过程:
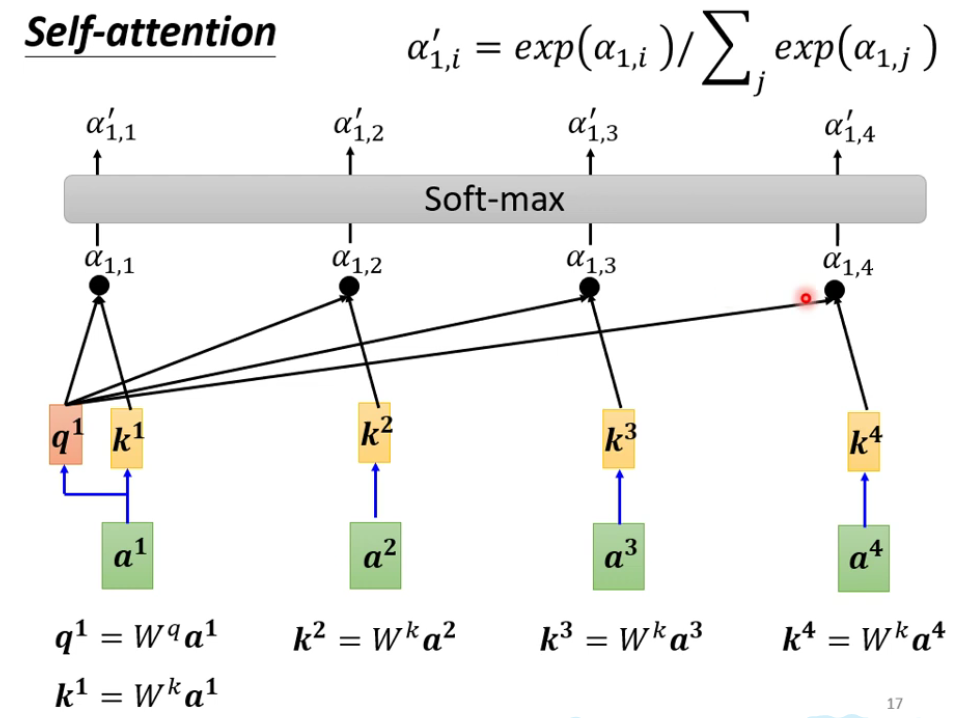
- ●代表dot-product;此处不一定要用soft-max
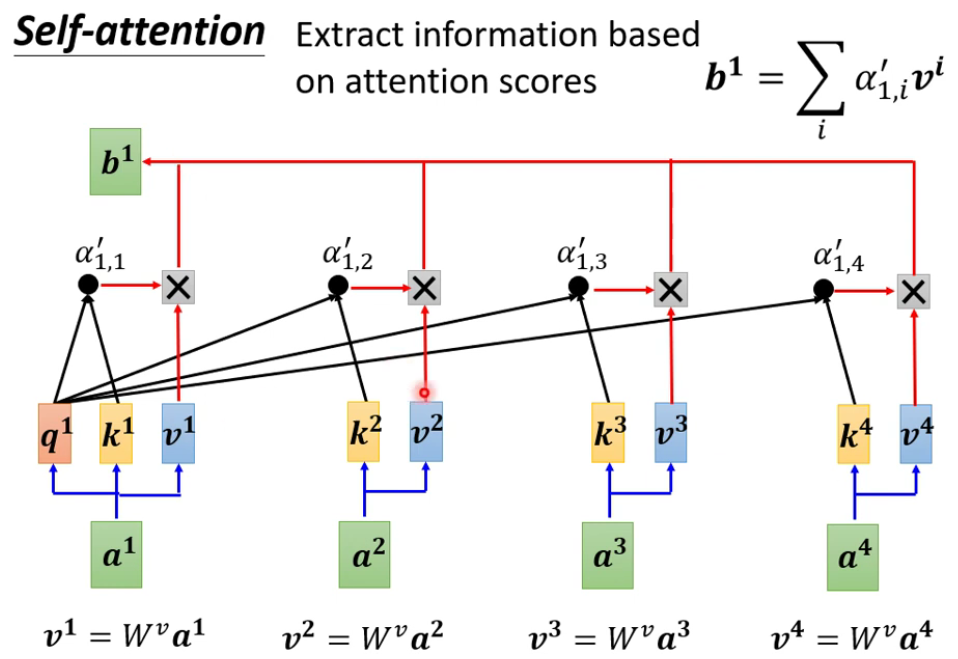
完整过程:
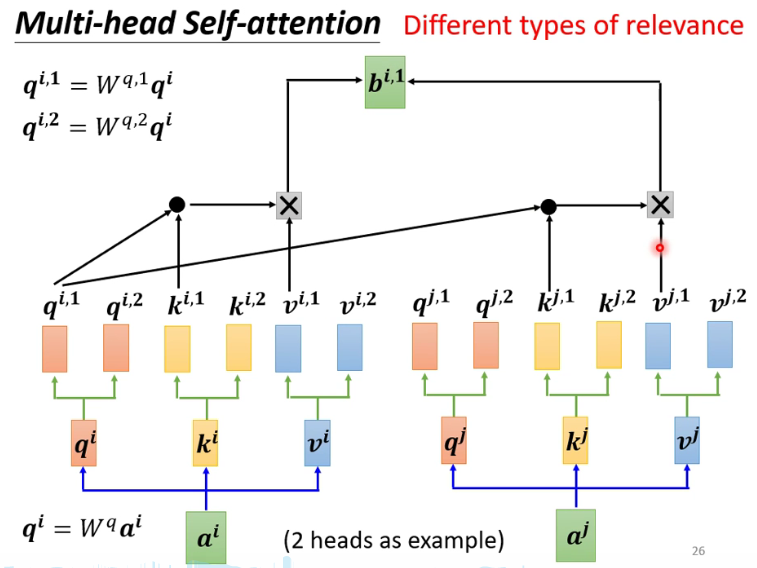
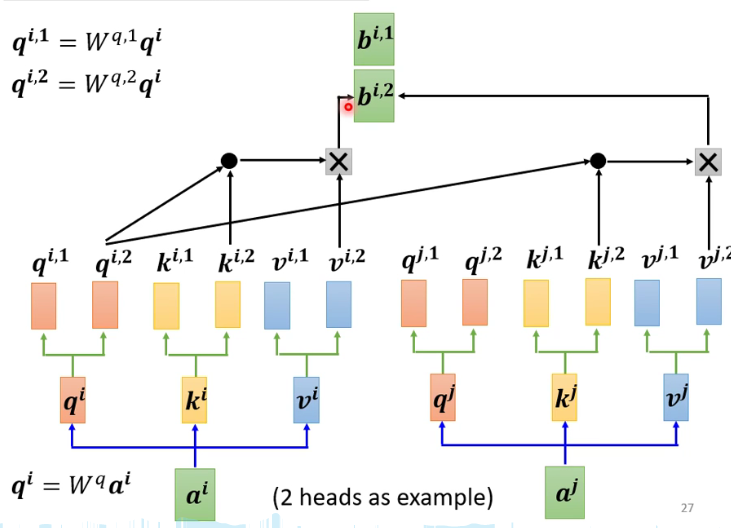
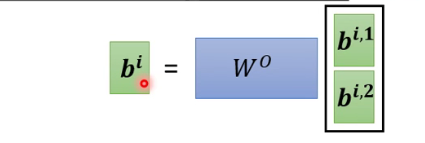
3.3 Multi-head Self-attention
寻找多种相关性。
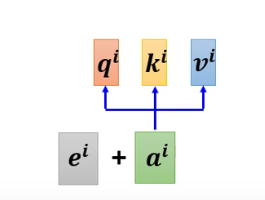
Positional Encoding
为每一个位置设置一个位置向量$e^i$。
3.4 其它变种
在语音辨识中,用于输入的数据很长,可以用Trancated Self-attention,只考虑每一段音频和周围的一定长度内的音频的关系。
Self-attention同样可以用于图片。
。。。
Self-attention vs CNN
。。。
Self-attention vs RNN
。。。
Self-attention for Graph
。。。