Eric Wang
August 30, 2021
大数据组件
大数据组件
Google的“三驾马车”:
- Google File System (GFS)
- 适用于大规模分布式数据处理的、可扩展的分布式文件系统
- MapReduce
- 一种用于大规模分布式数据的计算框架
- BigTable
- –一种构建在GFS之上的分布式数据库系统
1 Hadoop
Hadoop是Apache软件基金会旗下的一个开源的大数据处理框架。
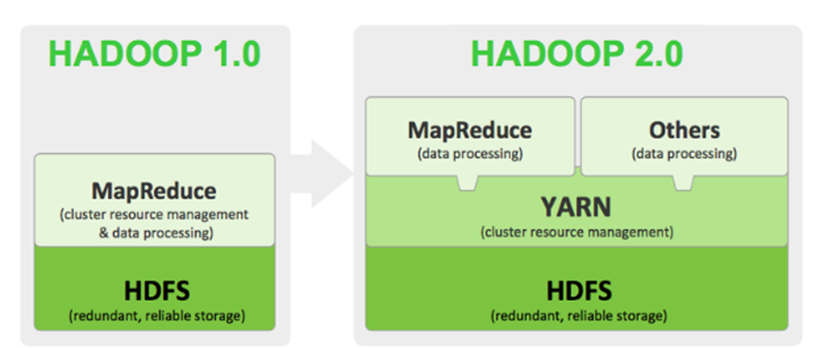
Hadoop基础架构
–NameNode:负责管理HDFS的元数据信息
–Secondary NameNode:协助NameNode管理HDFS元数据信息
–DataNode:负责实际数据的存储
–JobTracker:负责MapReduce作业管理、资源调度等
–TaskTrack:负责Map以及Reduce任务的执行和任务状态的回报
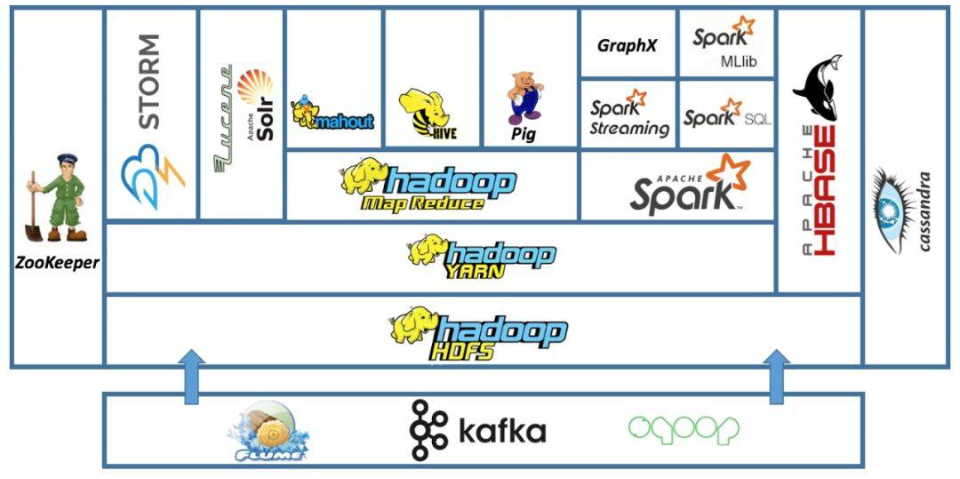
Hadoop生态系统
2 HDFS
- Hadoop Distributed File System
- 与MaReduce同为Hadoop的核心组件
- 块级别的分布式文件系统
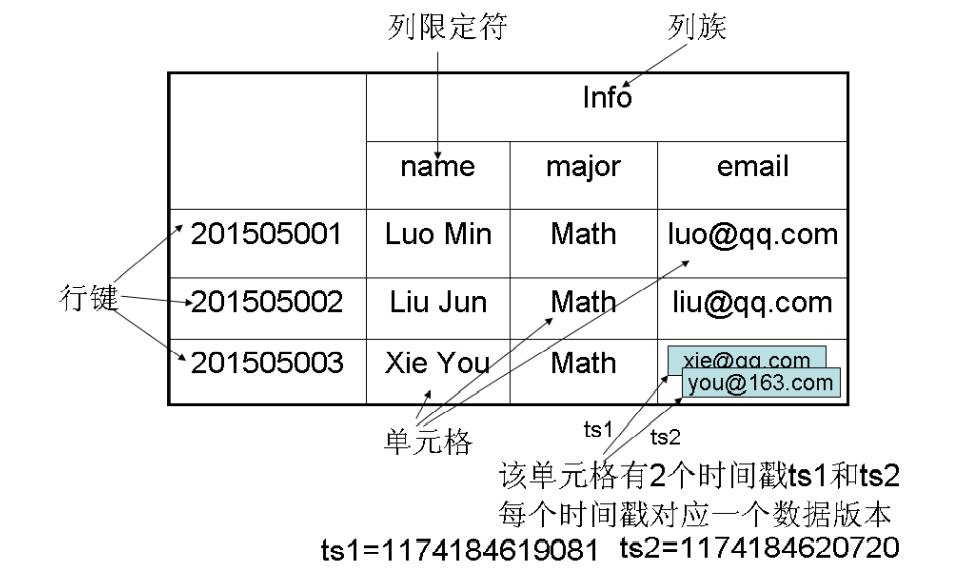
3 HBase
- HBase是谷歌BigTable的开源实现,因此,具有与 BigTable类似的特性
- 采用HDFS作为底层存储
- 依赖Zookeeper提供的分布式协调服务
与传统关系型数据库的区别:
- 数据类型:关系数据库采用关系模型,具有丰富的数据类型和存储方式;HBase则采用了更加简单的数据模型, 它把数据存储为未经解释的字符串。
- 数据操作:只有简单的插入、查询、删除、清空。
- 存储模式:基于列存储,每个列族都由几个文件保存,不同列族的文件是分离的。
- 数据索引:HBase只有一个索引——行键,HBase中的所有访问方法,或者通过行键访问,或 者通过行键扫描。
- 数据维护:在HBase中执行更新操作时,并不会删除数据旧的版本,而 是生成一个新的版本,旧的版本仍然保留。
HBase系统架构
- HMaster
- HMaster可以存在多个,主HMaster由ZooKeeper动态选举 产生
- 协调RegionServer
- 管理元信息
- ZooKeeper
- 内部存储着有关HBase的重要元信息和状态信息,担任HMaster与RegionServer之间的服务协调角色
- RegionServer
- 负责Region的存储和管理并与Client交互 处理读写请求
- Client
- Client提供HBase访问接口
- 与RegionServer交互读写数 据,并维护cache加快对HBase的访问速度。
4 Kafka
为了降低数据生产者和消费者之间的耦合度而引入的一层“中间件”。
Kafaka架构
- Producer:Producer将数据转化成“消息”,并通过网络发给 Broker。每条消息表示为一个三元组<topic, key, message>
- Broker:一般有多个,它们组成一个分布式高容错集群。Broker以追加的方式将消息写到磁盘文件中
- Consumer:主动从Broker拉取消息进行处理
在Kafka集群中,ZooKeeper担任分布式服务协调作 用,Broker和Consumer直接依赖于ZooKeeper才能正常工作。
5 Sqoop
为了解决关系型数据库与Hadoop之间的数据传输问题 ,Sqoop应运而生,它构建了两者之间的“桥梁”。

6 Flume
它是一个通用的流式数据收集系统,可以将不同数据源产生的流式数据近实时地发送到后端中心化的存储系统中。
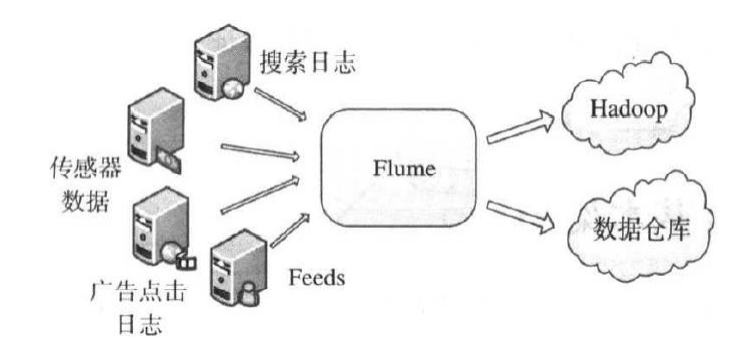
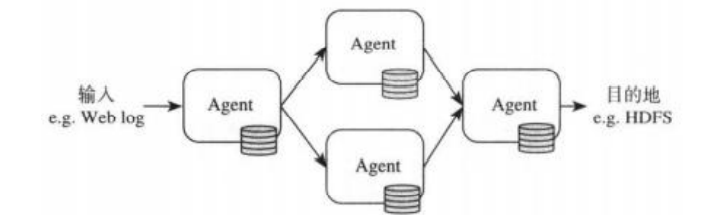
基本架构
数据源产生的流数据被一系 列Flume Agent收集(和处理),所收集的数据最终被送到 到目标(存储)系统。一个Agent可从客户端或上一个Agent 接受数据,经过过滤、路由,操作后传递给下一个或多个 Agent,直到抵达指定的目标系统。
Flume将数据流水线中传递的数据称为“Event”,每个 Event由头部和字节数组构成,其中,头部由一系列 key/value构成。
Flume Agent内部主要由三个组件构成:
- Source:数据的收集端,负责将数据捕获后进行特殊的格 式化,将数据封装到Event中,然后将Event推入Channel中
- Channel:一个缓存区,它暂存Source写入的Event,直到被 Sink发送出去。
- Sink:负责从Channel中读取Event,并将读取的Event发送 给下一个Agent(的Source)或持久化到存储系统。
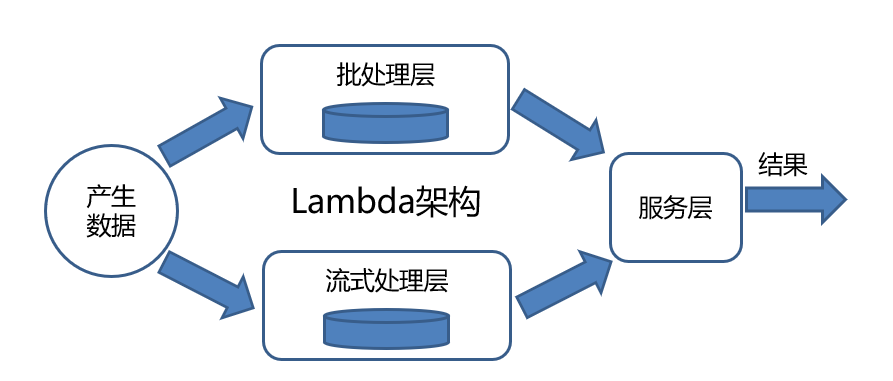
7 Lambda架构
一种大数据软件设计架构,其目的是指导用户充分利用批处理和流式计算技术各自的优点实现复杂的大数据处理系统。
批处理层:其优点是吞吐率高,缺点是数据处理延迟高,即从数据产生到最终被处理完成,整个过程用时较长
流式处理层:为了降低批处理层带来的高延迟,流式处理层被引入。缺点是无法进行复杂的逻辑计算,得到的结果往往是近似解。
服务层:批处理层和流式处理层可以结合在一起,这样既保证数据延迟低,也能完成复杂的逻辑计算。为了整合两层的计算结果,服务层被引入,它对外提供了统一的访问接口以方便用户使用。
推荐系统-Lambda架构的经典案例